比SBT更有价值的DAO声誉量化模型
 admin
2024-04-11 18:04:28
admin
2024-04-11 18:04:28
原文作者:TalentDAO@xrex
原文标题:Quantifying Reputation in DAOs
与 SBT 提供的单一定性数据点相比,声誉的定量模型可能更有意义。本文主要探讨在DAO网络中,如何量化贡献者声誉。在下一篇文章中,我们将探讨该量化模型框架对 DAO 治理的潜在影响。
几个前提假设
一个人在组织中的权力等于他的声誉;
声誉等于贡献;
贡献可以列举、衡量和量化;
对 DAO 贡献的整体量化可以实现完全透明、无需信任和公平的治理系统。
声誉是多维的
声誉是由多种因素构成的。我们选择观察哪些因素以及我们选择如何衡量它们会对我们做出的关于一个人的决定产生巨大影响;需要警惕涉及道德和伦理考虑的主观测量。诸如同行奖励圈(例如 Coordinape)之类的主观测量可以捕获未完全列举的贡献,同时还可以通过新的努力来激励新兴增长。但是,我将尽我所能在本文中坚持客观测量,并从逻辑第一原理思考问题。
如果组织中的新员工已经享有盛誉;然后,这是因为他们在其他地方做出的贡献——无论是在个人生活还是职业生活中。这些贡献赋予了他们可转让的声誉。
在 web3 世界中,匿名、隐私、抗审查、去信任和无许可系统正确地占据了至高无上的地位,在评估新组织或个人时,我们通常只能依赖声誉。因此,在确定某人在组织中拥有多少权力时,声誉非常重要。好在我们可以在链上跟踪行动,从而跟踪贡献。
DAO 贡献者可以通过参与聊天、论坛、投票、撰写提案、投票、参加会议、完成赏金和无数其他方式来建立声誉。这些行为可以通过各种方式量化,并使用代币进行奖励。不可转让的 NFT,即“灵魂绑定”代币 (SBT),在过去一年中已成为在链上发布信誉凭证的黄金标准。然而,这种方法不足以充分代表人类声誉的复杂性,尤其是在数字环境中。
一些创建人类声誉数字表示的方法确实包含了一组不同的输入数据源。声誉模型可以基于从链上和链下的各种数据源中提取的贡献,然后聚合或比较以计算给定指标和证书资格(“功勋徽章”)。这方面的几个例子是 Gitcoin Passport 和 Orange Protocol 的信誉 NFT。
使用模型可以让决策者微调他们对输入的选择。一方面是完全缺乏身份验证,另一方面是对所有列举变量的综合评估。与 SBT 提供的单一定性数据点相比,声誉的定量模型可能更有意义。
为什么组织使用 KPI
KPI 是衡量实现目标的绩效的一种手段。改进 KPI 不应成为任何计划的主要目标。这就像一条狗追逐它的尾巴。优化 KPI 并不能解决原始问题,并导致在不相关的数据集上“训练模型”。人类天生就有偏见和主观。人类不仅对他人撒谎,而且对自己撒谎,这种撒谎且往往是无意的。控制方法是使用客观的数据和分析。
什么是贡献?
具有无限设计空间的工作证明。
贡献包括:
一个动作/行为(工作)
结果(价值)
文件(工作证明)
四种贡献类型
治理:提案、投票、运营、审核
金融:投资、赠款、收购
努力:基于绩效和可交付成果的活动、在会议上花费的时间以及跟踪的项目工作
社交:聊天和论坛构思、反馈、会议、促销
贡献分数
通过跟踪和量化各种方式的贡献,有可能创建一个算法和整体系统,该系统对欺诈行为有很强的抵御能力,而且与较少的投入相比更具代表性、公平性和包容性。
需要建立不同级别的认证(证书)和获取规则,以区分个人贡献者和社区。每个人的行动都需要被列举出来。这似乎是一项艰巨的任务,直到我们对这个过程施加一些结构。
可以使用转换函数对个人贡献进行归一化,然后进行时间过滤以调整其相对权重。然后可以根据元函数聚合任何特定贡献的权重,该元函数根据每个社区特定的分布(下面进一步描述)缩放贡献类型的类别。最终结果是生成一个单一的汇总值,我们将其描述为“贡献分数”。
转换函数:数据转换
线性:x = n
“图形为直线的函数,即次数为零或一的多项式函数。”
二次方: x = 2^n
“具有一个或多个变量的多项式函数,其中最高阶项为二阶。”
对数:x = log2(n);
求幂的反函数。”\”另一个固定数字 [...] 必须提高到的指数”
时间过滤器
可以调整每个输入以关注相关时间范围或加权时间范围,以确定发送到转换函数的计数中包含哪些贡献。本节和概念最初受到 SourceCred grain 分布中使用的模型的启发。
SourceCred 对于项目如何为贡献分配奖励(“grain”)有三种政策——最近的、即时的和平衡的。此处介绍的模型将其扩展到包括信念——一种在给定时间段内增加输入权重的策略。
时间过滤器的概念可以应用于计算任何给定快照的贡献分数。
1.即时
“这将根据每个参与者在上周的贡献平均分配奖励。(此政策忽略前几周的所有贡献,旨在为积极参与者提供快速奖励)。”
2.平衡
“这会根据终生贡献和终生奖励收入来分配奖励。平衡的时间过滤器试图确保项目中的每个人都收到与他们在整个参与期间的总贡献一致的总奖励支付。
例如,假设一个贡献者过去贡献的数量很少,因此获得的奖励也很少。但是,社区最近改变了权重,或者添加了一个新的插件,使得贡献者现在有更多的贡献记录。
平衡政策认为这个贡献者的报酬过低,所以它会支付额外的钱来“赶上”项目中的其他人。相反,贡献者可能会‘多付’,他们会得到更少的回报,直到支出被平衡。”
3.最近
“这会根据最近的贡献分配奖励,使用指数衰减来优先考虑最近的信誉。“recentWeeklyDecayRate 参数决定了你想在多大程度上关注最近的贡献。如果 recentWeeklyDecayRate 设置为 0.5(即 50% 折扣),如上例,该策略将计算上周产生的贡献的 100%,前一周产生的贡献的 50%,本周产生的贡献的 25%在那之前,前一周的 12.5%,依此类推。”
4. 信念
有第四种可能的模式作为治理的修饰符而流行,可用作时间贡献过滤器。信念投票结合了随着时间的推移不断增加决策承诺的概念。可以扩展相同的概念,以根据随时间而不是固定时间段连续衰减的权重来计算贡献分数。
输出
因变量是通过适当的时间过滤转换函数传递输入变量而产生的。表 1(分为两部分)说明了输入 (X) 的示例列表,并将每个输入与假设方法配对以计算输出值 (Y)。
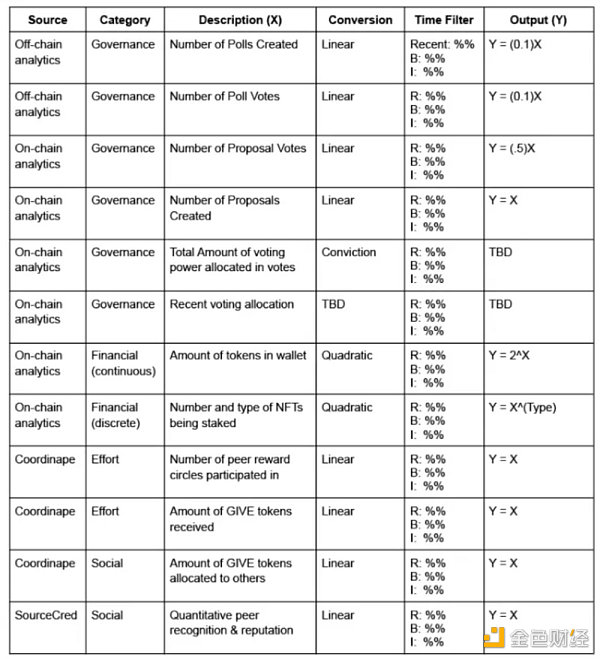
图1:具有丰富输入集的说明性模型组件
元函数
元函数在这里被定义为由集合函数组成的复合函数。集合函数的一个属性是相对于一组输入函数减少计算的维度输出。元函数可用于计算标准化的贡献分数,该分数合理地近似于社区中基于声誉的参与。从一组输出值 (Y) 计算标准化贡献分数需要三个步骤,这些输出值表示每个单独贡献的输入源的缩放和标准化量化。
确定每种贡献类型的权重。
治理:XX%
财务:XX%
努力:XX%
社交:XX%
注意:如果贡献被分配给多种类型,则它们必须单独计算。
确定用于组合贡献类型的转换函数。
(a) + (b) + (c) + (d) = 总重量
注意:对所有元函数使用线性转换并避免多余的数据转换可能更简单。通过使用适当的转换函数转换每个单独的输入,可以获得更精细的控制。
通过取总权重的平均值来归一化最终的贡献分数。
总权重/# 贡献类型 = 归一化贡献分数
若非特殊说明,文章均属本站原创,转载请注明原链接。

- 周排行
- 月排行
-
从供需角度看香港加密现货ETF的影响
2024-05-05 -

TON生态热度再起 Elfbird精灵鸟能否成为下一个奇迹
2024-11-12 -

币圈沉浮史:从一堆空气到美金30000亿
2024-11-12 -

Web3 代币设计的正确打开方式
2024-07-28 -
香港证监会更新警示名单 总数达39家
2024-07-28 -
由特朗普NFT项目引发的合规思考
2024-07-28
-
从供需角度看香港加密现货ETF的影响
2024-05-05 -
TON生态热度再起 Elfbird精灵鸟能否成为下一个奇迹
2024-11-12 -
币圈沉浮史:从一堆空气到美金30000亿
2024-11-12 -
Web3 代币设计的正确打开方式
2024-07-28 -
香港证监会更新警示名单 总数达39家
2024-07-28 -
由特朗普NFT项目引发的合规思考
2024-07-28
最近发表
-
FTX 及其 23 起诉讼:受骗的投资者会重见正义吗?
2024-11-13 -
AI代理与加密货币的双向进化:从GOAT代币的兴起看科技与法律的对抗与平衡
2024-11-13 -

OKX 高校访谈|Aleksandar:钱包即服务对Web3至关重要
2024-11-13 -

比特币收买的美国政客 已经占领了整个国会
2024-11-13 -
早报 | 不丹BTC持有量目前占其GDP三分之一 美元升至两年高位
2024-11-13 -

八年前梭哈以太坊 这位加密亿万富豪为何迷上了长寿科学?
2024-11-13 -
晚间必读5篇 | BTC六年疯涨25倍
2024-11-12 -
Galaxy:加密进入黄金时代 华盛顿会发生哪些变化
2024-11-12 -
币圈沉浮史:从一堆空气到美金30000亿
2024-11-12 -
TON生态热度再起 Elfbird精灵鸟能否成为下一个奇迹
2024-11-12