DePIN打猎之旅:AI算力作饵,道阻且长
 admin
2024-04-12 18:04:28
admin
2024-04-12 18:04:28
作者:Hedy Bi,OKG Research
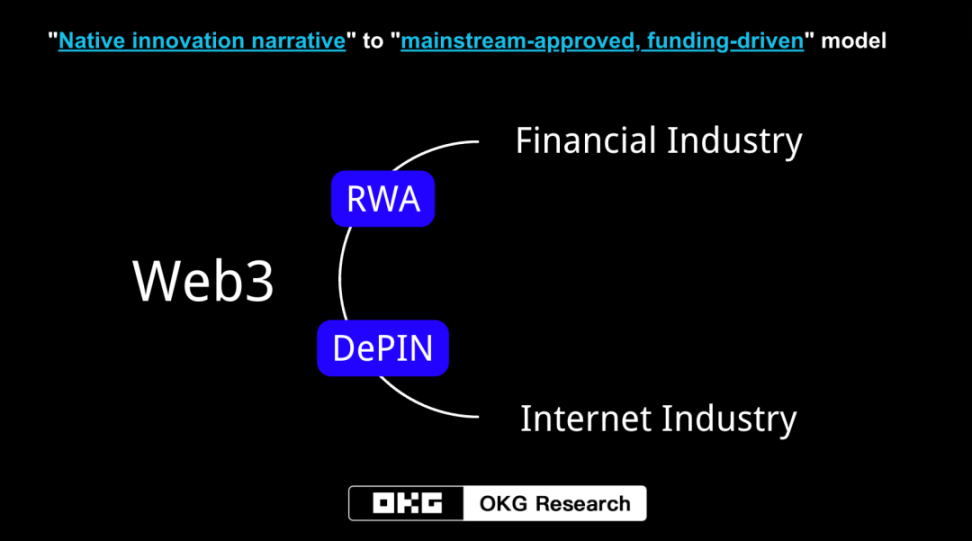
香港 Web3 嘉年华已告一段落,然而 Web3 自由的脉搏还在跳动,并不断向其他行业渗透。和上一轮周期相比,本轮牛市开启的逻辑是由「原生创新叙事」转变成「主流认可,资金驱动」的模式。笔者所观察到的 Web3 发展阶段也从一个「封闭且小众的绝对自由」,演变到了「真正包容下的相对自由」阶段。
在这样的逻辑下再不跳出盒子去分析,守株待兔原生创新叙事已无法适应 Web3 当下的发展。自整个 Web3 拥抱合规开始,Web3 已经在港府的不断推动下,重新聚焦金融领域。主流金融机构也通过 RWA、现货 ETF 加速参与 Web3。
此次大会,除了主流金融机构进入 Web3,我们也看到了一个可以连接 Web2 和 Web3 的机会—— DePIN 赛道。尤其是 AI 大模型发展的推动,让 DePIN 中的子赛道 - 算力的重新分配再次成为热门关注。
算力为诱饵,但 AI 大模型训练并不是 DePIN 最好落地场景
「区块链是通过技术建立信任,而 AI 又是一个极度需要信任的行业。」Dragonfly Capital 的管理合伙人 Haseed Qureshi 在大会如是说。
DePIN 并不是一个新赛道,早在几年前就已经提出。正是 AI 大模型爆发,业界对于算力和数据开展了大量的讨论,据测算,大模型计算的成本每年增加 31 倍。全球 GPU 短缺,英伟达这样的公司处于目前市场需求的食物链顶端具有极大的定价权。垄断还是去中心化,有关于成本之辩成了 Web3 DePIN 赛道再次热议的原因。
虽然 AI 大模型训练是起因,但罗马非一日建成,AI 大模型训练并不是目前 DePIN 最好的落地场景。AI 大模型生产对算力的要求主要围绕 2 个方面:推理和训练。在训练环节,通过投喂大量的数据,训练出一个复杂的神经网络模型。在推理环节,利用训练好的模型,使用大量数据推理出各种结论。
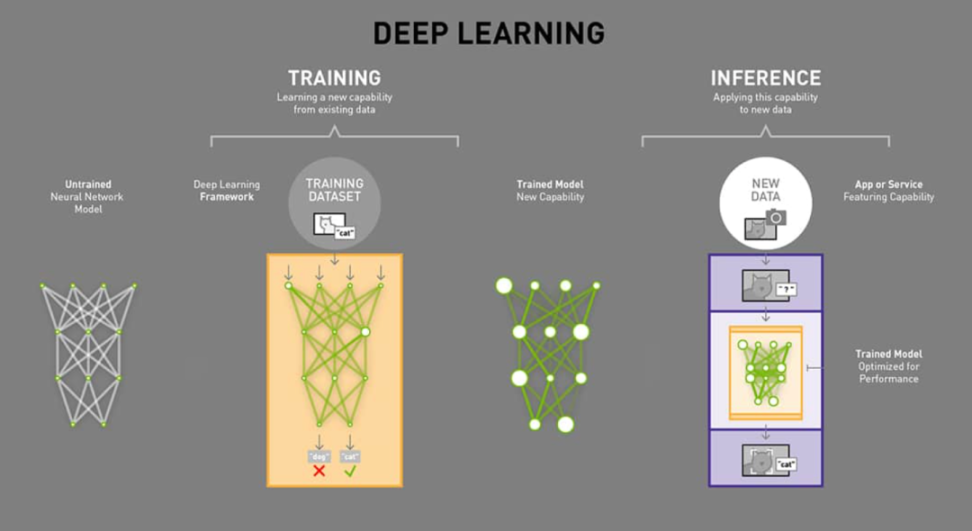
去中心化与算力的结合,难度系数从训练到微调训练再到推理是逐层递减的。在 DePIN 中,可以看到行业上更多的项目是集中在推理而非训练的。大部分企业的 AI 训练采用的英伟达 GPU 集群主要原因是其拥有自身强悍的并行计算能力以及内存带宽。相对于推理环节,对于并行计算能力和带宽的要求降低很多。并且大模型训练对于稳定性更为看重,因为一旦训练中断,是需要重新进行训练的。若在以太坊上构建一个去中心化算力应用供 GPT 使用,仅单个矩阵乘法运算将消耗 Gas 费高达 100 亿美元并且需要 1 个月之久。
此外,笔者分析了此次大会中比较热门的几个项目现状,呈现供给端超过需求端的一个态势,即分布在全球的算力供给超过 AI 模型训练或者推理任务的 AI 开发者需求。并不是说需求不存在,OpenAI 的创始人 Sam Altman 提出了要募集 7 万亿美金,构建一个超过目前台积电 10 倍规模的先进芯片厂和用于芯片的生产和模型训练。斯坦福大学研究也表明,不论哪个语言模型,当训练参数规模超过那个规模的临界值后,其表现(比如准确性)就急剧提升。这与「大力出奇迹」的规律截然相反,也意味着现实情况下,去中心化算力的设想还有很多难题去解决。
DePIN 赛道的「历史溯源」可追溯至「共享经济」
DePIN 本身概念不难理解,甚至可以追溯到 Web2,回顾互联网行业,至少有 15 年时间,Web2 玩家沉浸于将个人的有形资产聚合起来,从而创造出「共享经济」之中。如果是将无形资产(例如闲置的服务器等)直接通过 Peer to peer(P2P)的形式或者 Peer to business(P2B)的形式重新分配给需求方,去中心化技术区块链就可以通过激励机制来进行生产关系的一个优化。这就是 DePIN 要做的东西。
也因此,DePIN 赛道下面,大家在供给端的热情是高涨的。其实 Web2 已经为「重新分配」做了很久的积淀,只是这次,直接去掉中介。目前已有近千个 DePIN 项目,尤其是 Solana 生态,据 Messari 统计,Solana 生态在 DePIN 基础设施处于领先地位,这是由于 Solana 公链具有较高的基础设施集成性和性能。在地区分布上,预计多个前 10 名的 DePIN 将在 2024 年至 2025 年来自亚洲。

Web3 和 AI 有非常多的交叉点,算力作为未来数字世界的通用货币,是人们最先关注到的。但去中心化算力这个最合理的落地场景却不是最容易落地的。
在 Web3 与 AI 的交叉点上,除了从技术上攻坚克难不断突破这样的难题外,还有其他很多分支例如 AI 代理的赋予创作者所有权以及小型 AI 模型算力场景值得探索,会更具有落地性。商业模式的成功和技术的突破总会有所平衡,DePIN 正在加速这一进程,DePIN 的「打猎之旅」也会满载而归。
若非特殊说明,文章均属本站原创,转载请注明原链接。

- 周排行
- 月排行
-
从供需角度看香港加密现货ETF的影响
2024-05-05 -

TON生态热度再起 Elfbird精灵鸟能否成为下一个奇迹
2024-11-12 -

币圈沉浮史:从一堆空气到美金30000亿
2024-11-12 -

Web3 代币设计的正确打开方式
2024-07-28 -
香港证监会更新警示名单 总数达39家
2024-07-28 -
由特朗普NFT项目引发的合规思考
2024-07-28
-
从供需角度看香港加密现货ETF的影响
2024-05-05 -
TON生态热度再起 Elfbird精灵鸟能否成为下一个奇迹
2024-11-12 -
币圈沉浮史:从一堆空气到美金30000亿
2024-11-12 -
Web3 代币设计的正确打开方式
2024-07-28 -
香港证监会更新警示名单 总数达39家
2024-07-28 -
由特朗普NFT项目引发的合规思考
2024-07-28
最近发表
-
FTX 及其 23 起诉讼:受骗的投资者会重见正义吗?
2024-11-13 -
AI代理与加密货币的双向进化:从GOAT代币的兴起看科技与法律的对抗与平衡
2024-11-13 -

OKX 高校访谈|Aleksandar:钱包即服务对Web3至关重要
2024-11-13 -

比特币收买的美国政客 已经占领了整个国会
2024-11-13 -
早报 | 不丹BTC持有量目前占其GDP三分之一 美元升至两年高位
2024-11-13 -

八年前梭哈以太坊 这位加密亿万富豪为何迷上了长寿科学?
2024-11-13 -
晚间必读5篇 | BTC六年疯涨25倍
2024-11-12 -
Galaxy:加密进入黄金时代 华盛顿会发生哪些变化
2024-11-12 -
币圈沉浮史:从一堆空气到美金30000亿
2024-11-12 -
TON生态热度再起 Elfbird精灵鸟能否成为下一个奇迹
2024-11-12